머신러닝 모델이 적합한 결과를 내기 위해서는 여러번의 최적화 과정을 거친다. 다루어야 할 데이터가 많기도 하고, 메모리가 부족하기도 하기 때문에 한번의 계산으로 최적화된 값을 찾는 것은 어렵다. 따라서 최적화(optimization)를 할 때는 일반적으로 여러번의 학습과정을 거친다. 또한, 한번의 학습 과정도 사용하는 데이터를 세분화하여 진행한다. 이때 Training Epoch, Batch Size, Iteration 그리고 Learning Rate라는 개념이 필요하다.
Training Epoch
한번의 epoch은 인공신경망에서 전체 데이터 셋에 대해 forward pass/backward pass 과정을 거친 것을 말한다. 이 말인 즉슨, 전체 데이터셋에 대해 한 번 학습을 완료한 상태를 뜻한다. 이렇게 두 과정을 학습하는 과정을 묶어 역전파 알고리즘(back propagation algorithm)이라고 한다. 해당 알고리즘은 신경망의 파라미터를 사용하여 입력부터 출력까지 각 계층의 weight를 계산하는 순방향 패스(forward pass), 순뱡향을 반대로 거슬러 올라가며 다시 한 번 계산하여 weight를 수정하는 역방향 패스(backward pass)로 나뉜다고 정의할 수 있다. 이 전체 데이터 셋에 대해 역전파 알고리즘 진행이 완료되면 한 번의 epoch이 진행됐다고 볼 수 있다. 만약, epochs = 40이라면 전체 데이터를 40번 사용해서 학습을 거치는 것이다.
따라서 적당한 epoch 값을 설정해야 최적화된 하이퍼 파라미터를 찾을 수 있다. 만약 epoch 값이 너무 작다면 underfitting이 발생하고, epoch 값이 너무 크다면 overfitting이 발생할 것이다.
Batch Size과 Iteration
하나의 epoch을 돌 때 메모리의 한계와 속도 저하를 막기 위해 전체 데이터를 쪼개서 학습한다. 쪼개진 데이터를 batch라고 하고 그 크기를 batch size라고 한다. 하나의 epoch에 데이터를 나눌 때 몇 번 나누어서 주는지를 iteration이라고 한다.

Learning Rate
미분 기울기의 이동 step을 말한다.
lr값이 작다는 것은 기울기의 이동 step의 간격이 작아진다는 의미를 갖는다. 그러면 학습을 하는 과정에서 속도가 매우 느리게 될 것이다. 만약 data를 학습하는 과정의 반복이 적을 경우 최솟값에 도달하기도 전에 (lr의 이동 스텝이 늦어서) 원하는 최솟값을 가질 수 없게된다. 학습을 하고 있는 과정에도 cost 값이 거의 변하지 않는다면 lr의 값이 매우 작다는 것을 의심해봐야 한다.
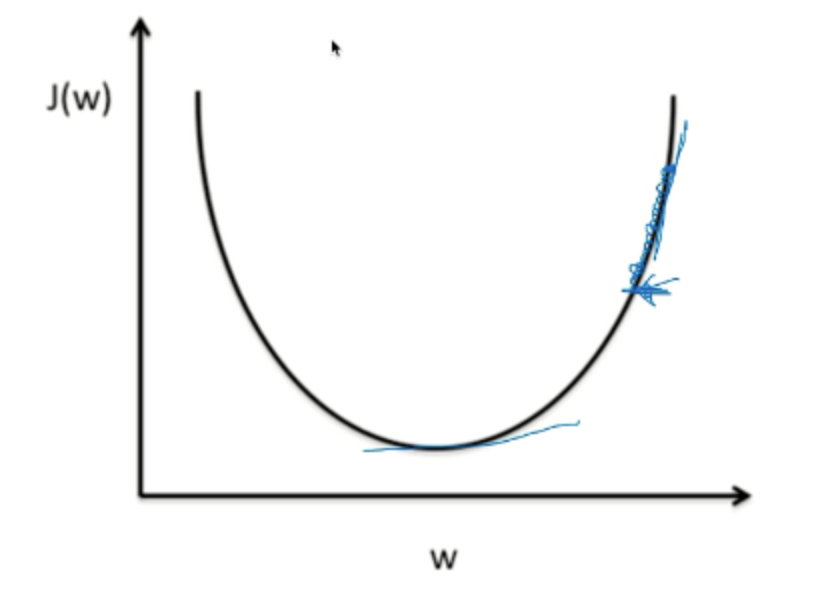
lr값이 크다는 것은 기울기의 이동 step의 간격이 커진다는 의미를 갖는다. 너무 값이 커지면 반대쪽 그래프로 이동하여 그래프를 벗어나는 결과 값을 도출 할 수도 있다. 이러한 경우를 overshooting이라고 한다.
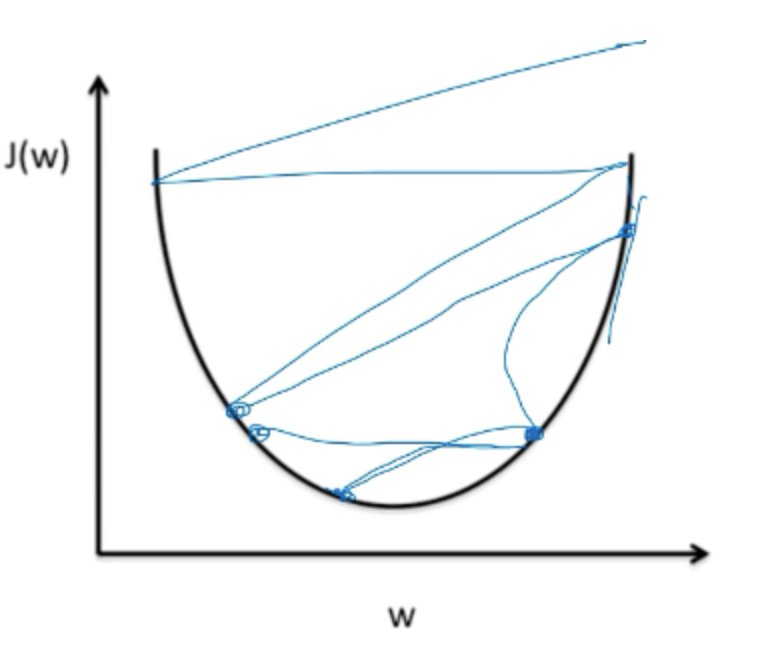
따라서 lr을 매우 적절하게 설정하는 것이 매우 중요하다. 대부분의 lr 값은 0.01로 시작해서 overshooting이 일어나면 lr의 값을 줄이고, 학습속도가 매우 느리다면 lr의 값을 올리는 방향으로 학습을 진행한다.
참고
'AI > 개념' 카테고리의 다른 글
| Batch Normalization, Drop out (0) | 2021.06.08 |
|---|---|
| [CS231n] 2강 정리 (0) | 2021.06.08 |
| Overfitting과 Underfitting (0) | 2021.06.07 |
| Torchvision 패키지 (0) | 2021.03.03 |